
Introduction
Web scraping is a term used to describe the automated process of extracting data from websites, crucial for various industries. Python emerges as the preferred choice for its simplicity and powerful libraries like BeautifulSoup, a popular web scraping tool. In this article, we’ll explore the fundamentals of web scraping using Python, including using Python for web scraping, and explain the role of BeautifulSoup as a key tool for the task.
Web Scraping Using BeautifulSoup
In today’s digital age, the internet is a treasure trove of valuable data. From e-commerce product listings to recipe databases, the wealth of information available online is immense. Web scraping using Python has become an indispensable tool for efficiently extracting this data. Python, known for its versatility, offers a variety of libraries for web scraping using Python, with BeautifulSoup being one of the most popular libraries.
Understanding Web Scraping
It involves fetching and parsing the HTML content of web pages to extract desired information. Web scraping is the act of scraping information from a web application. Using Python for web scraping is renowned for its versatility and offers a variety of libraries, with BeautifulSoup being one of the most popular libraries. Using BeautifulSoup, developers can navigate through the HTML structure of web scraping sites and extract specific data points with ease.
What Is Beautiful Soup for Web Scraping using Python?
Beautiful Soup, a vital tool for web scraping using Python, empowers Python developer skills. With its methods for navigating, searching, and manipulating parse trees within HTML and XML files, this library simplifies the transformation of intricate HTML documents into a structured tree of Python objects. Additionally, Beautiful Soup handles Unicode conversion, eliminating encoding concerns. Beyond aiding in data extraction, it enhances Python developer skills by facilitating data cleaning, making Python more efficient for web scraping tasks.
To install Python and Beautiful Soup, follow these steps:
- Open your terminal or command prompt.
- Type the following commands to download Python and Beautiful Soup libraries:

Python and BeautifulSoup: A Powerful Combination
The code example provided demonstrates how to leverage these tools to extract ingredients and recipes from a webpage. By sending a GET request to the specified URL and parsing the HTML content using BeautifulSoup, developers can efficiently navigate through the webpage’s structure and extract relevant information from web scraping sites.
1. import requestsfrom bs4
2. import BeautifulSoup
3.
4. # Send a GET request to the webpage URL using requests library
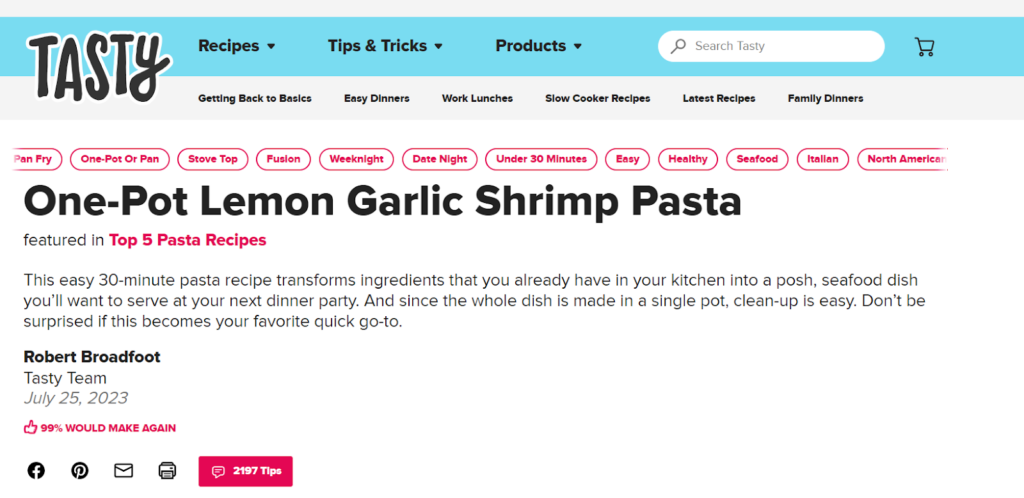
5. req = requests.get("https://tasty.co/recipe/one-pot-lemon-garlic-shrimp-pasta")
6.
7. # Parse the HTML content of the webpage using BeautifulSoupsoup
8. Soup = BeautifulSoupsoup(req.content, "html.parser")
9.
10. # Assign the recipe name
11. recipe_name = "One-Pot Lemon Garlic Shrimp Pasta"
12.
13. # Find the element containing ingredients
14. ingredients_element = soup.find('div', class_='ingredients__section')
15.
16. # Extract ingredients
17. ingredients = ingredients_element.text.strip() if
17. ingredients_element else "Ingredients not found"
18.
19. # Print the extracted recipe name and ingredients
20. print("Recipe Name:", recipe_name)
21. print("\nIngredients:", ingredients) Code Explanation
- Line 1: Import the requests library which allows sending HTTP requests.
- Line 2: Import the Beautiful Soup library which provides methods to parse and navigate through HTML documents.
- Line 5: Send a GET request to the specified URL and store the response object in variable ‘req’.
- Line 8: Create a Beautiful Soup object by parsing the HTML content of the requested page with the html.parser module. The resulting object can be used to search for elements within the parsed HTML.
- Line 11: Define a string variable for storing the recipe name. In this case, it is hard coded as the recipe being scraped has no unique identifier or label for its title.
- Line 14: Search for the first <div> tag having the CSS class named ‘ingredients__section’ inside the parsed HTML document, and save the result into the variable ‘ingredients\_element‘.
- Line 17: If ‘ingredients_element’ exists, remove any leading/trailing whitespaces from its textual content and assign it to the ‘ingredients’ variable. Otherwise, set ‘ingredients’ to the value “Ingredients not found”.
- Line 20: Prints the recipe name, represented by the value stored in the variable ‘recipe_name’.
- Line 21: Prints the extracted ingredients, represented by the value stored in the variable ‘ingredients’, preceded by a newline character for formatting.
Conclusion
In conclusion, web scraping using Python with BeautifulSoup is a powerful technique for extracting data from web scraping sites. Python for web scraping provides versatility and simplicity, enabling efficient data extraction. This method, along with other web scraping tools, facilitates automated data collection, making it essential for diverse applications in data acquisition and analysis.
FAQs
Ans: Web scraping involves extracting data from websites. For instance, Python for web scraping allows users to automate data collection processes efficiently, making it a valuable skill in various fields.
Ans: Web scraping efficiently automates data extraction from websites, enabling retrieval of specific information for analysis, leveraging Python for web scraping tools.
Ans: Web scraping, the process of automating data extraction from websites, commonly utilises the Python library BeautifulSoup, simplifying parsing HTML and navigating website structures for efficient data extraction.
Ans: In Python, web scraping using BeautifulSoup and requests libraries automates data extraction from websites. This versatile approach streamlines the process, making Python an effective tool for web scraping tasks.
Read Some Latest Blogs
- Data Science vs Data Analytics: Top Key Differences for Success

- How To Become A Data Scientist In India?: Achieve Your Data Scientist Dreams

- What are Callback Function in JavaScript?: A Guide to Effective Implementation

- Top 9 Interview Questions and Answers for Freshers Success

- What Is Python and Its Dynamic Uses?
